{kind=link}
Supervised and Unsupervised One of the most capable artificial intelligence (AI) fields is machine learning (ML). This subset allows computers to “learn” to do tasks via examples and experience. For several years now, many research and development (R&D) efforts in the ML space have successfully produced technologies with many real-world applications. Almost everything you see today, such as programmatic advertising technologies used by digital marketers and automated recommendations from Netflix, is power by ML algorithms that learn from your past preferences and activities.
But while ML is indeed becoming mainstream, it comes in different forms. This post will dig deeper into two types of ML algorithms—supervised and unsupervised learning—and attempt to point out how exactly they differ.
Table of Contents
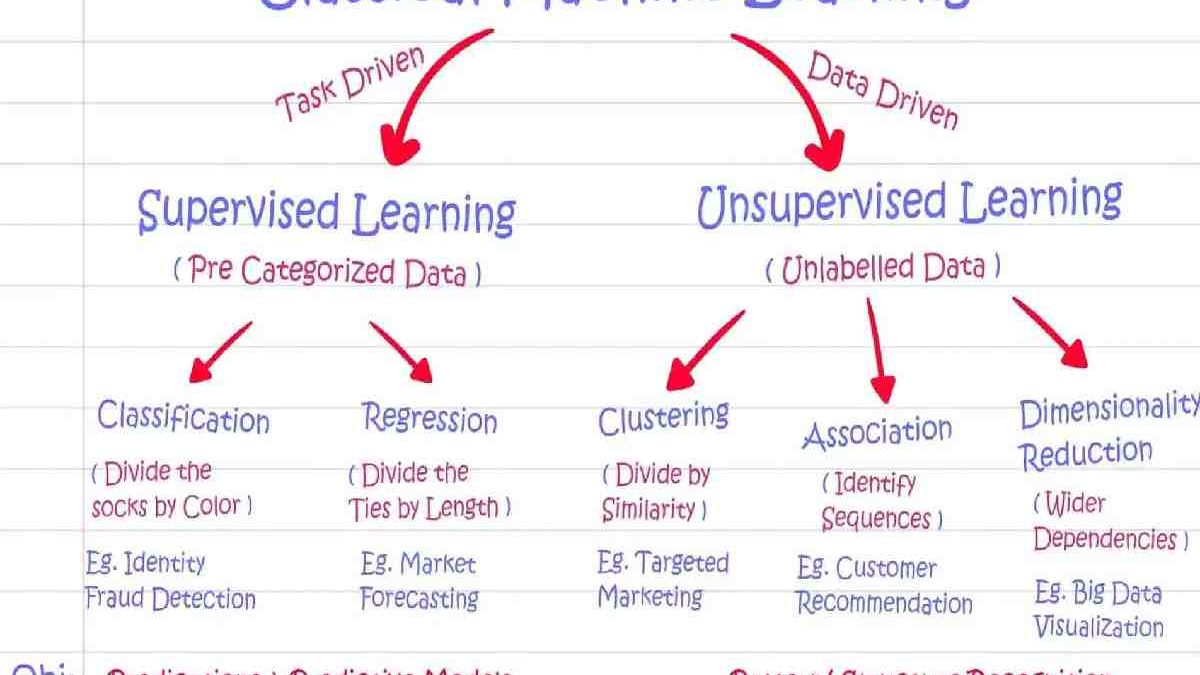
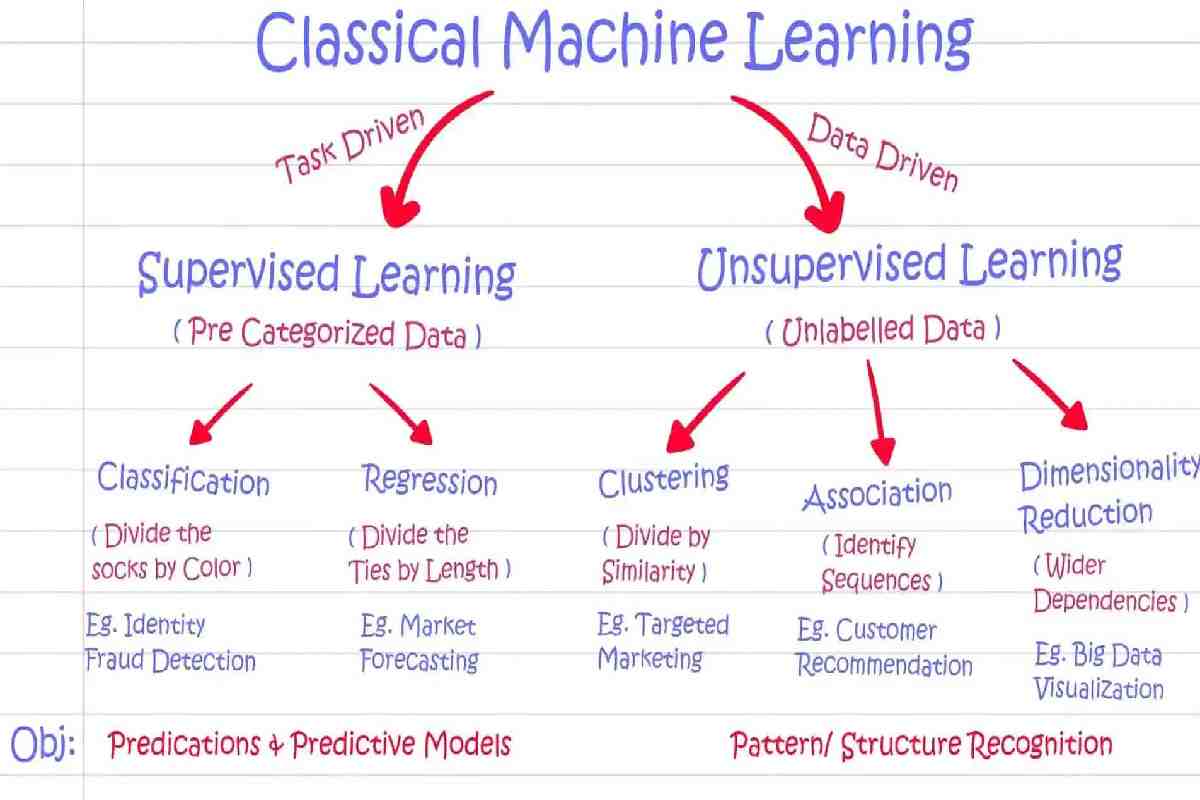
What is Supervised Learning?
Supervised learning is responsible for teaching a machine or system to do tasks using several training methods that follow a desire output or goal. Like its name, the process requires observation and guidance to ensure that tasks or projects push through. Supervised learning is thus best applied to jobs with known outcomes, such as classifying objects. An example of this is training neural networks.
The training process involves feeding a machine with named data, which it will use to predict outcomes. In the case of artificial neural networks (ANNs), the dataset contains the input pattern or information that the system can use to derive its output. That pattern would train the system to achieve a specific work.
So, say you want to develop an ML-powered image classification algorithm that can identify the presence of cars, trucks, and boats. To effectively train the system, it must first have many images of cars, trucks, and ships that it needs to classify before getting fed to the algorithm as inputs. Once done, the pictures with their corresponding annotations would undergo mathematical modelling to map an image to its proper classification accurately.
What is Unsupervised Learning?
Unsupervised learning, meanwhile, does not require an output pattern. That means the system would not receive any form of training. The learning process ensues by allowing the machine to spot notable characteristics from input patterns independently. Instead of getting train, the systems conclude unable datasets, just like how humans learn from satisfying their curiosity. Infants, for example, need not be introduced to crawling on their own. They know to do so because they want to help their curiosity
Unsupervised learning is apply to complex algorithms because there is little to no usable information from datasets. It does so by searching for clusters or groups to estimate each kind of object’s number, for instance.
You are running an e-commerce shop and have to deal with troves of customer data. You want to segment your customers according to buying habits so that you can craft marketing strategies effectively. Since you do not have predetermine categories to group them, it would be impossible for you to use supervised ML. That is where unsupervised learning comes in. Since it doesn’t require labelled datasets, a machine can crawl data and divide inputs into groups based on their shared characteristics.
What’s the Difference Between Supervised and Unsupervised Learning?
In sum, both supervised and unsupervised learning are changing the ML landscape regarding how systems learn and produce outputs. But while supervised learning requires labelled datasets and a predetermined result, unsupervised learning does not. That said, systems capable of unsupervised learning go through a much more complicated process than those designed for supervised learning. Finally, while supervised learning may process data offline, unsupervised learning requires a constant connection to datasets and potential sources for analysis.
While there are mark differences between supervised and unsupervised learning, there is no doubt that both are require to make even more significant strides in the ML space. As both techniques progress, we’ll see more innovations in the ML and AI fields.
Conclusion
Unsupervised learning starts from previously unable data. Supervised learning assumes that we start from a once label data set. We know the value of the target attribute for the data set that we have.